
Designing an AI-Agent Marketing Team: What Actually Works
- Yumi

- Mar 10
- 17 min read
Updated: Apr 22
I run a team of four AI agents that handle marketing operations across two products. They scan competitors, draft articles, publish to WordPress, validate contacts, fix SEO issues, and coordinate through a shared workspace. Most of the workflow is automated, but I stay in the loop to check execution, review results, and make the calls that matter. The system replaced what used to cost close to $10,000/month in contractor fees with roughly $800 to 900/month in API and subscription costs, and gave me back 30+ hours a week I was spending on tasks that are now fully scheduled. Here's how I got here, what the architecture looks like after four months of iteration, what breaks, and what it would cost to do the same work with people.
Contents
Background: Why I Started Building This
Getting Started: OpenClaw, Model Selection, and Vibe Coding
How the Agent Team Evolved
Temporary vs. Persistent Agents
The Local Knowledge Base: QA Gate for Content
What They Actually Do Day-to-Day
Real Work Beyond Content
What Breaks: Fixable vs. Not Fixable
What This Would Cost with People
Brand Separation: A Lesson Learned
What Keeps It Running: The Infrastructure
What I'd Do Differently
What This Means at Scale
Background: Why I Started Building This
I'm a startup founder running two products with a small team. LEAD is an HR/People Ops tool for knowledge sharing and employee matching. BehaviorGraph is an enterprise AI platform for organizational intelligence. Both need content, competitive intel, SEO, outreach , the full marketing stack.
Before the agents, I tried the conventional route. Over the past couple of years I hired contractors through platforms like Upwork and Indeed: content writers, SEO specialists, research assistants from the US, UK, Philippines, Bangladesh, and other places. Every hire went through interviews and test projects. Some were good. Most were expensive for what they delivered.
The pattern was always the same: 2 to3 months of onboarding before anyone was productive with our products and voice. Then, just when they got up to speed, the best ones would start interviewing at other startups offering US-level rates. We were already paying above local market, but early-stage startup budgets can't compete with Series B companies hiring from the same talent pools. Founder capital is hard-won. Every dollar in that budget came from somewhere: investor trust, revenue we hadn't spent, time we could have put into product. Watching it go toward onboarding someone who leaves in four months is painful.
The quality issue was the other half. For the price of a part-time US content writer, I'd get SEO articles that technically hit the keyword targets but read like they were written by someone who'd never used our product. Competitive intel reports that summarized a competitor's About page instead of tracking what actually changed. The work got done, but the judgment wasn't there. And judgment is the part you're really paying for.
Eventually I let the contractors go and went back to doing everything myself. But I was already stretched across product, research, fundraising, and customers. There weren't enough hours in the week for content, SEO, outreach, and competitive monitoring on top of everything else. Something had to give.
In March 2026, I started building agents with OpenClaw. The pitch to myself was simple: if the agents can match the quality of the contractors I was hiring (and they can, because the bar wasn't that high), then I get consistency, zero onboarding time, no retention risk, and a fraction of the cost. Two months in, the agents produce better content than most of the contractors did, and they run every single day without me asking.
Getting Started: OpenClaw, Model Selection, and Vibe Coding
I started with OpenClaw, an open-source agent orchestration framework. The initial plan was to use GPT for everything. I had high hopes for it, but the harness on the OpenClaw side wasn't tuned right for OpenAI's API at the time. The agents kept hitting rate limits, and coding tasks (writing scripts, editing files, calling APIs) would stall or fail mid-run. After a few frustrating weeks I switched the orchestrator to Claude Sonnet. It took maybe a few minutes to swap the model config, and the difference was immediate: reliable tool use, consistent instruction following, and no more rate limit walls during complex multi-step tasks.
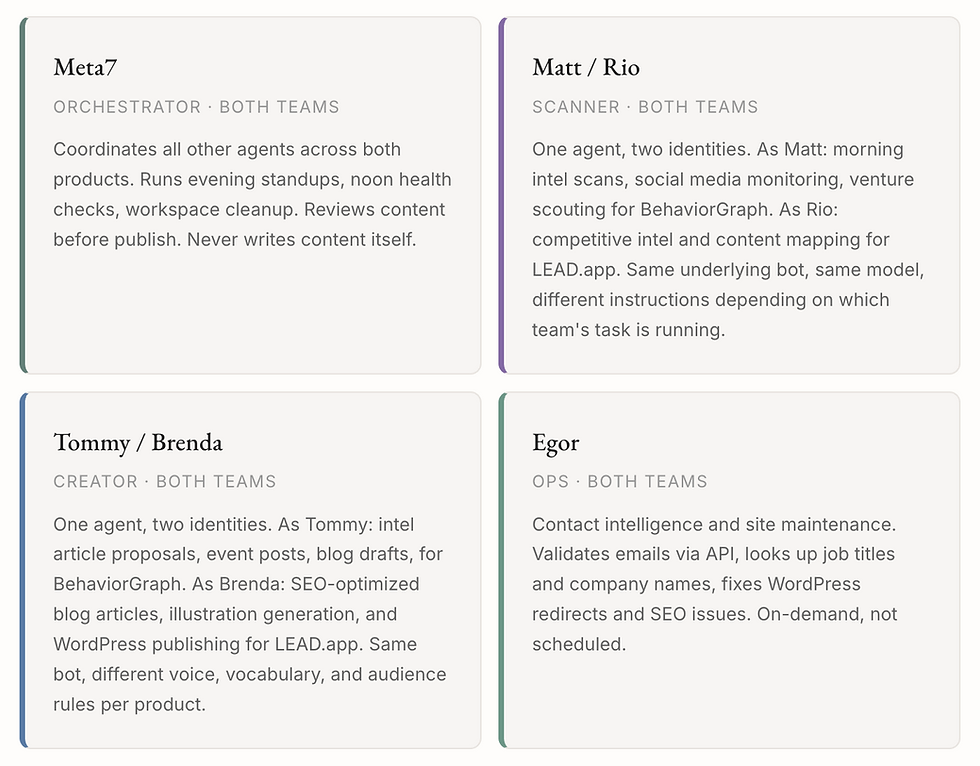
The first thing I built was the master agent, Meta7. I wrote all the original configuration files myself: his identity, his standing orders, his memory structure, and the identity and rules for each of his sub-agents. Every agent started as a set of markdown files that defined who they are, what they do, and what they're not allowed to do. That foundation matters because it's what the agents read every time they wake up for a task.
Once Meta7 was stable, I gave him certain rights to override some of my original settings when he could justify it. If a schedule wasn't working, he could adjust it. If a sub-agent's skill file had a gap, he could patch it. The key constraint: he logs every override so I can review what changed and why. This turned out to be one of the best decisions in the whole setup. The system improves itself between my sessions, but I always have a paper trail.
Most of the day-to-day building happens through what people now call vibe coding: describing what I want to an AI coding assistant and iterating on the output in conversation. I'm not a software engineer by training. I'm a product person who can read code, spot when something is wrong, and describe what I want clearly enough for the AI to build it.
That works for a lot of things: agent skills, scheduling logic, dashboard features, infrastructure scripts. But for anything that touches product design, how the agents coordinate, what the review gates look like, which decisions require human input, I write a proper design spec first. The spec is the thinking. The AI handles the implementation. Skipping the spec for important architecture decisions is how you end up rebuilding the same thing three times.
The rule I follow: if the decision is reversible (a script, a style change, a cron schedule), vibe code it. If the decision shapes how the system behaves for weeks (agent roles, data flow, brand rules), write the spec.

How the Agent Team Evolved
How the Agent Team Evolved
The first version was one orchestrator, Meta7, with four temporary sub-agents (bots that spin up for a task and disappear). Each team had two: one for search and one for content plus illustration. The content bots used two models, GPT for writing and Nano Banana for image generation. Keeping search and content separate was a model-role fit decision from day one: each agent type maps to the model whose cost-performance profile matches its workload. Search needs a cheap, fast model that can run dozens of queries. Content needs a model that writes well. Bundling them would mean overpaying for search or underperforming on writing.
That setup worked until the scope grew. I added new bots for isolated tasks: competitive intel scanning, contact enrichment, event curation. Each one made sense individually, but collectively they created a coordination explosion: Meta7 had to manage conflict-free scheduling (making sure agents don't run overlapping tasks on shared files), review more outputs, and run more quality checks. The orchestration overhead, the tokens Meta7 spent just keeping track of everyone, started costing as much as the work itself.
The turning point was building the local cost and performance tracking app. It does token-level cost attribution (breaking down spend by provider, model, and agent per task, not just monthly totals). Once I could see exactly how much each bot was spending per task, the waste was obvious. Some bots were running expensive models for simple search work. Others were duplicating context reads across every session. Meta7 was burning tokens just keeping track of everyone. The data made the case for consolidation clear.

The restructured system uses four agents: an orchestrator, a scanner, a creator, and an ops agent. The key insight was that the scanner and creator each have two identities, one per product. The scanner runs as Matt for BehaviorGraph intel and as Rio for LEAD competitive scans. The creator runs as Tommy for BehaviorGraph content and as Brenda for LEAD articles. Same underlying bot, different instructions, voice, and vocabulary depending on which team's task is running. The orchestrator (Meta7) coordinates across both.
Why not merge scanner and creator into one agent? Model economics. Scanning is high-volume, low-cost work that needs a fast, cheap model for dozens of web searches. Content creation needs a model that writes well, follows nuanced brand rules, and handles long-form drafting. Forcing both tasks through the same model either overpays for scanning or underperforms on writing. Splitting by role lets each agent run on the model that fits its actual workload.

Temporary vs. Persistent Agents
There was another important evolution in the first month. Initially all the agents were temporary: they spun up for a task, did the work, and disappeared. Every session started from scratch, reading all the context files, skill definitions, and memory documents before doing anything. Meta7 even recommended staying with temporary agents because the per-session cost looked lower on paper.
But I noticed the context loading was eating a significant chunk of every run. A content agent that needs to understand the brand voice, the last 14 days of published articles, the editorial rules, and the current proposal queue is reading thousands of tokens before it writes a single word. Multiply that by four daily publish slots and the "cheaper" temporary agent is spending more on context reads than a persistent one would.
After the first month I switched to persistent agents. Each agent maintains long-term memory across sessions using external memory files (markdown on disk, outside the model's context window). They already know the brand rules, the recent history, and the recurring patterns. They still read fresh data (today's intel scan, the latest proposals), but the foundational context is already in memory and doesn't need to be re-loaded every session.
This is essentially prompt cache optimization: the stable parts of the agent's knowledge live in persistent memory rather than being re-injected as tokens on every call. The upfront cost per session is higher, but the total cost over a week is lower because you're not re-teaching the same agent the same things every single run.
The Local Knowledge Base: QA Gate for Content
One problem with AI-generated content is grounding. A language model can write a confident, well-structured article that sounds authoritative but contains claims nobody at the company has ever validated. For a startup trying to build credibility, that's dangerous.
The fix was building a local knowledge base (we call it KMspace) that acts as a QA gate for all published content. It's not a generic RAG setup (retrieval-augmented generation, where you throw documents into a vector database and hope the model finds relevant chunks). It's a structured, maintained knowledge workspace with a formal ingest, qualification, and promotion pipeline. Data enters as raw intake, gets scored and filtered, and only graduates to the canonical wiki layer after passing quality gates:

The wiki layer contains validated claims (thesis-map, use-cases, claims-and-guardrails), an evidence log with sourced entries, and voice models that define how each writing style should sound. Every content proposal from Tommy or Brenda must anchor to at least one wiki claim and one evidence entry. If a proposal can't point to something in the knowledge base, it doesn't move forward.
A nightly ingest job pulls qualified signals from Matt's daily scans into the raw layer, normalizing them into a consistent schema so downstream agents don't have to handle format differences between sources. A separate lint-and-heal process runs weekly to check for broken cross-references, orphaned claims, and entries that have gone stale. Think of it as garbage collection for knowledge: it keeps the wiki layer internally consistent so agents don't build on outdated foundations. The wiki layer is the single source of truth. The agents read it. I maintain it. Nothing gets published that can't trace back to something real.
This solves the biggest quality problem with AI content: the model sounds confident whether it's right or wrong. The knowledge base doesn't make the model smarter. It gives me a checkpoint. If the agent cites a claim that exists in the wiki with a real source behind it, I can trust the content. If it can't anchor, the draft gets rejected before it reaches the review gate.
What They Actually Do Day-to-Day
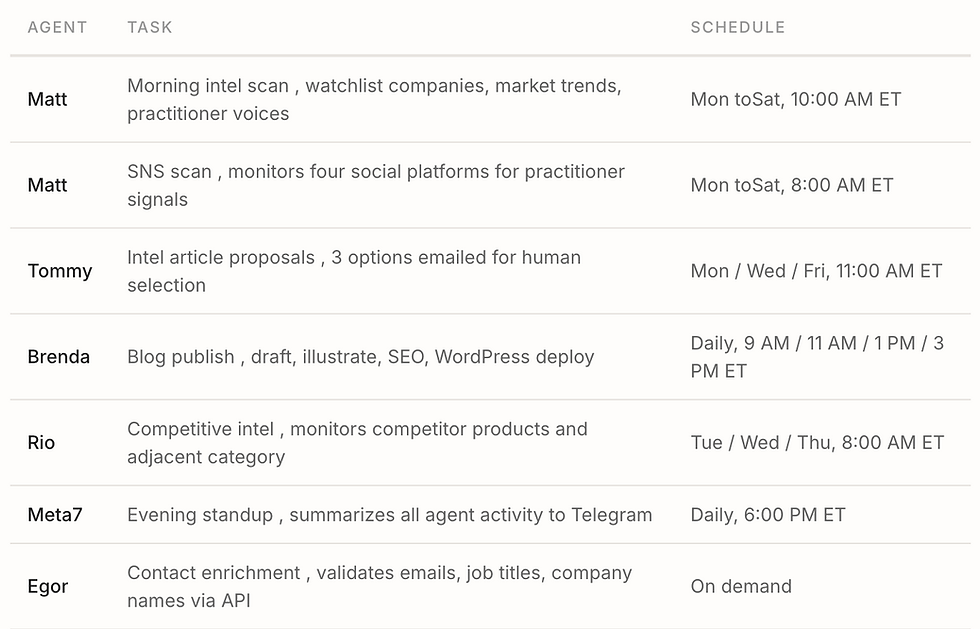
The system runs on scheduled jobs: tasks that fire automatically at set times, like alarm clocks for AI workers. In engineering terms, these are cron jobs, named after a Unix scheduling utility that's been around for decades. The concept is simple: "run this task at this time, on these days."
Real Work Beyond Content
Content is the most visible output, but the agents handle a lot of operational work that doesn't produce blog posts:
Contact enrichment. Egor calls external APIs to validate email addresses, pull current job titles and company names, and flag contacts that have gone stale. This runs before any outreach campaign so we're not sending to dead addresses or wrong titles.
WordPress maintenance. Fixing broken redirects, diagnosing crawl errors, updating meta descriptions, and resolving SEO issues that search tools flag. Brenda handles this as part of her publishing workflow rather than as a separate task.
What Breaks: Fixable vs. Not Fixable
Four months in, the failure modes fall into two clean categories: things I can fix with better engineering and things that are API or platform limits I have to live with.
What I can fix
Email delivery from background sessions. Agents running on a schedule can't always reach the system mail client. Fix: a watchdog, a small automated checker that runs every 30 minutes, finds stuck emails, sends them, and marks them done. Think of it as someone walking the floor to make sure nothing got stuck.
Laptop sleep killing scheduled jobs. Half of our cron failures were the Mac going to sleep. Fix: a script that prevents sleep when plugged into AC power. Infrastructure doesn't have to be sophisticated to matter.
Brand cross-contamination. One product's terminology leaked into the other product's blog content. Fix: vocabulary firewalls in agent skills, terminology translation tables, and mandatory automated checks before publishing.
Orchestrator scope creep. The coordinator started giving editorial suggestions on articles, which wasn't its job. Fix: tighten the review gate to checklist only, word count, illustration exists, title matches. No wording changes.
Workspace bloat. Agents generate a lot of artifacts: scan reports, draft proposals, run logs, intermediate findings, qualification records. Left unchecked, the workspace fills up with repeated entries, stale data, and unqualified signals that nobody will ever use. This adds noise for the agents too, since they read these files for context, so bloat directly increases token cost and degrades output quality. Fix: a weekly automated cleanup that consolidates duplicates, archives things that didn't carry forward, and deletes unqualified raw intake. The orchestrator runs this every Sunday as a two-phase idempotent job (meaning it's safe to re-run if interrupted; it produces the same result whether it runs once or twice). Curation first, then cleanup. Not glamorous, but it keeps the workspace lean so agents aren't paying to read garbage every morning.
What I can't fix (API and platform limits)
The rate limit / cost trap. API providers like Anthropic and OpenAI assign you a usage tier based on how much you've spent. Spend more, get higher rate limits (more requests per minute, more tokens per minute). Sounds good, except: when agents aren't hitting rate walls anymore, they run longer sessions, make more calls, and use more tokens per task. The per-token price doesn't change, but the total bill goes up because the agents expand to fill the available capacity. Tasks that used to fail halfway and save partial results now run to completion, which is better quality but costs more. I haven't figured out whether the right answer is to artificially constrain the agents or let them run and pay for the quality. Probably somewhere in between.
Growing context per session. This is the hidden cost multiplier. Each API call within a session includes the full conversation history. Call #1 might send 2,000 tokens, but call #10 sends those 2,000 plus everything from calls 1 through 9. A 15-call session doesn't cost 15x the first call. It costs much more because the later calls carry the full accumulated context. Even a simple task at the end of a long session is expensive because it's paying for the entire conversation weight. This is why persistent agents with long-term memory can actually save money: the memory replaces in-session context loading.
Model output inconsistency. The same prompt can produce different quality output on different runs. Some days a draft is sharp; some days it's generic. There's no fix for this, it's the nature of language models. The review gate catches the bad ones, but it means not every scheduled run produces publishable work.
Third-party API reliability. Email validation services, image generation APIs, and web scrapers all have their own uptime issues. When the illustration generator is down or a data source returns errors, the agent logs the failure and moves on. Retry logic helps, but some runs just don't complete.
What This Would Cost with People
The honest question: could I just hire people to do this? Yes. Would it cost more? Significantly. Here's the comparison for the core tasks the agents handle, priced against contract rates in Canada and Western Europe (where I'd realistically hire remote marketing help):

That's roughly a 10x cost difference. But the real comparison isn't agents vs. a senior hire , it's agents vs. the contractors I was actually hiring. And honestly? The agents produce better work for most of these tasks. They follow the brand rules every time. They don't paraphrase the competitor's About page and call it research. They don't need 2 to3 months of onboarding to understand the product.
Where humans still win: judgment, taste, and surprise. A great content strategist would find angles the agents never will. A senior researcher would connect dots across conversations that don't appear in any search result. For the 10 to 20% of the work that requires that kind of thinking, I still do it myself. The agents handle the other 80% that's structured and repetitive.
The hidden savings go beyond the dollar figure. No onboarding. No retention risk. No negotiating rates every quarter. No coverage gaps when someone takes a vacation or leaves for a better offer. The agents run every single morning, scan every competitor update, publish on schedule, and report what they did by 6 PM. For an early-stage founder watching every dollar, that predictability matters as much as the cost.
Brand Separation: A Lesson Learned
We run two products with different audiences and different language. LEAD speaks to HR people who think in terms of "virtual coffee chats" and "5 minutes per month." BehaviorGraph speaks to enterprise AI architects who think in terms of governance and organizational intelligence.
The agents didn't know that at first. The intel agent's reports started using BehaviorGraph terminology in recommendations for LEAD blog content. The term even leaked into a published article before I caught it.
The fix: a vocabulary firewall in the intel agent's skills, a terminology translation table in the content creator's publishing rules, and a mandatory automated check before any article goes live. The rule is simple , if a term from Product A appears in Product B's content, the agent rewrites it before proceeding.
What Keeps It Running: The Infrastructure
A few patterns that turned out to be essential:
Scheduled jobs (cron). Every agent task runs on a defined schedule , like setting an alarm clock. The system fires the task at the right time; the agent wakes up, does its work, and stops. No always-on processes burning money. The orchestrator can retrigger missed jobs at noon if something went wrong in the morning.
Watchdogs. Small, frequent automated checks that catch failures before they compound. The email watchdog runs every 30 minutes and catches stuck deliveries. The noon recovery sweep checks whether morning scans actually ran and retriggers anything that was missed. Think of these as safety nets , they walk the floor so you don't have to.
Isolated sessions. Each agent runs in its own sandbox. One creator can't accidentally read the other's draft. The orchestrator can review content but can't edit it. This prevents the brand cross-contamination problem.
Human-in-the-loop at decision points. The agents don't decide what to publish. The creator sends three article proposals; I pick one. Another creator drafts and illustrates; the orchestrator holds at a review gate. Automation handles the 90% that's repetitive; I handle the 10% that's judgment.
What I'd Do Differently (What I Learned the Hard Way)
I'm not an engineer by training. A lot of what I know about running agent infrastructure, I learned by breaking things and then figuring out why. The git history of this project tells the story: 26 commits over two weeks, most of them fixes for problems I didn't know existed until they happened. Here's what I wish I'd known on day one.
Agents will hang, and you won't know. My scans would start, run for 40 minutes, and produce nothing. No error, no crash, just silence. I didn't know that a process can stall without failing. It took me a week of debugging to learn that I needed a watchdog that checks whether an agent is still producing output, not just whether it's still running. The fix was a stall detector with a 3-minute CSV-output timeout and a 10-minute absolute cap. I had five commits in one day (April 14) just getting scan reliability right.
"Success" doesn't mean it worked. One of my scan pipelines was reporting success on empty result sets. The agent ran, found nothing, wrote an empty CSV, and logged "completed." From the dashboard it looked fine. I only noticed because the intel reports downstream were empty for three days. The lesson: validate outputs, not just exit codes. An agent that finishes without producing useful output is worse than one that crashes, because at least a crash triggers an alert.
When jobs fail, simplify them. This was the single biggest reliability lesson, and it took me a few rounds to learn it. My first instinct when a job failed was to add more: new skills, more retry logic, better error handling in the prompt. I'd ask Meta7 to fix the failure by editing the skill or creating a new one. Sometimes that helped. But most of the time, the real problem was that the job was doing too much in the LLM layer.
My early cron jobs asked the LLM to grep files, reason about the results, decide what to do, compose a message, and send it via Telegram, all within a 2 to 5 minute timeout. They'd time out constantly. The PENDING_EMAIL watchdog had 6 consecutive errors, all timeouts. The noon check-up timed out. The job scan had 3 consecutive timeouts.
The fix that actually worked wasn't adding complexity. It was the opposite: push the logic into bash scripts, keep the LLM job prompt minimal and fast. The PENDING_EMAIL watchdog went from an LLM scanning files, parsing metadata, and sending email within 120 seconds, to a single bash script call that finishes in 11 to 19 seconds. The noon check went from 300-second timeouts to completing in 13 seconds. The HN submission went from timing out at 20 minutes (because it was waiting for a Telegram reply inside the cron run) to finishing in 92 seconds by sending the preview and exiting immediately.
The day before the fix: 6 jobs consistently erroring. The day after: all green. The pattern is simple. If a cron job is timing out, the answer is almost always "the LLM is doing work that should be a script."
Don't use an LLM for everything. My first version of the HN/Reddit scanner used the LLM to call the API, parse the response, and filter results. It cost 10x what it should have. I rewrote it as a direct API collector: a simple script calls my local scanner app API, the LLM only handles the qualification step at the end. Not every agent task needs a language model. Some things are just HTTP calls and JSON parsing.
You'll go through agents fast. In the first week I created Nina (QA agent), Berry, and Grabber. By April 11, all three were removed. Each one made sense when I created it, but the coordination cost of Meta7 managing them was more than the value they added. If I'd built the cost tracking dashboard first, I would have seen this before committing to the architecture. Instead I spent a week building agents and another week consolidating them.
Brand rules are invisible until they leak. I didn't think about vocabulary separation between my two products until BehaviorGraph terminology showed up in a published LEAD article. That's not a technical failure. It's a governance failure, and as a non-engineer I didn't have the instinct to build vocabulary firewalls proactively. An experienced systems architect would have scoped the brand boundaries before the first article was written. I learned it by reading the wrong words on a live page.
Spec the decisions, vibe-code the rest. I rebuilt the agent coordination layer twice because I jumped straight to vibe coding without specifying role boundaries. The implementation was fast both times. The rework was slow because I had to untangle decisions that were baked into code instead of written down. Now I write a one-page spec for anything structural and let the AI handle everything else.
What This Means at Scale
This agent team is both a practical solution and an experiment. It solves a real bottleneck: two products that need marketing, no budget for a full team. But it's also shown me how many things you already need to think about even at the smallest possible scale: one human, four agents, one orchestrator, one monitoring app.
I only talk to Meta7. He routes everything. When something breaks, the local monitoring app flags it independently. Even so, I've already dealt with brand vocabulary leaking across products, the orchestrator overstepping its role, agents conflicting on shared files, silent delivery failures, workspace pollution, and jobs failing because the laptop was asleep.
Now imagine twenty humans and sixty agents. People giving contradictory instructions to the same agent. Someone changing a setting that another person's agent depends on. Feedback that conflicts with earlier feedback and nobody remembers which is current. Logs everywhere but too many to read, so issues hide in plain sight. Content polluted because multiple humans and agents are writing to the same knowledge base with different assumptions.
The governance for that world doesn't exist yet. The hard problems aren't "can the agent write a blog post." Those are solved. The hard problems are human-to-agent conflicts, agent-to-agent conflicts, settings drift, log overload, and accountability gaps. Who's responsible when wrong content goes out, the human who gave the brief, the agent who wrote it, or the orchestrator who approved it?
Everything I've described in this article is just one human with a small team of agents, and it already requires serious infrastructure. The multi-human, multi-agent version of this problem is an order of magnitude harder, and it's the one most companies will actually face.



Comments